Commentary
Commentary

Affiliation:
1Alzheimer’s Drug Discovery Foundation, New York, NY 10019, USA
ORCID: https://orcid.org/0000-0002-8296-7623
Affiliation:
1Alzheimer’s Drug Discovery Foundation, New York, NY 10019, USA
Affiliation:
2Gates Ventures, Kirkland, WA 98033, USA
Affiliation:
1Alzheimer’s Drug Discovery Foundation, New York, NY 10019, USA
ORCID: https://orcid.org/0000-0002-0015-1357
Affiliation:
2Gates Ventures, Kirkland, WA 98033, USA
3Circadic, Arlington, MA 02476, USA
4Clinical & Translational Science Institute, Tufts University Medical Center, Boston, MA 02111, USA
Email: lampros@circadic.io
ORCID: https://orcid.org/0000-0003-1332-0655
Explor Med. 2020;1:359–363 DOI: https://doi.org/10.37349/emed.2020.00024
Received: August 24, 2020 Accepted: October 20, 2020 Published: December 31, 2020
Academic Editor: Lindsay A. Farrer, Boston University School of Medicine, USA
The article belongs to the special issue Digital Biomarkers: The New Frontier for Medicine and Research
This commentary is the product of a concerted effort to understand the needs, barriers, and gaps in the field of speech and language biomarkers for Alzheimer’s disease (AD). It distills interviews, surveys, and extensive correspondence with global leaders in the areas of dementia research, clinical trials, linguistics, and data analytics into an idealized clinical-study design for the harmonized collection of voice recordings. The ultimate goal of the effort is to democratize the ongoing speech and language analytics efforts by making such rich datasets available to the wider research ecosystem.
Successful drug development for Alzheimer’s disease (AD) depends on clinicians’ ability to diagnose and monitor the disease’s progression—especially via clear, measurable biomarkers that can detect subtle changes in patients’ pathologic neuronal decline long before they show other, more serious symptoms. Alterations of speech and language are showing promise as possible early biomarkers of AD [1].
Researchers can collect and analyze speech and language information using new and improved technology, hardware and data analytics. Likewise, ubiquitous use of smart devices enables remote data collection, both active (prompted by the user) and passive (without user prompts). These tools can measure acoustic features such as pitch and amplitude, as well as lexical and syntactic aspects of speech and features of written language such as text contextual or semantic information—all of which are associated with early AD and its progression [2, 3].
Yet researchers have not been able to fully take advantage of the opportunities these tools can offer. To optimize speech and language biomarker discovery, researchers need a comprehensive speech-sample repository that covers a large, diverse cohort of subjects representing different accents, languages, speech and language components, and disease stages. They also need state-of-the-art participant characterization along with harmonized protocols and standards that cover the types of speech and language samples. These activities are nearly impossible for most research groups or startups to achieve on their own due to the costs associated with participant characterization [such as repeated positron emission tomography (PET) scans, magnetic resonance imaging (MRI), and blood-based biomarkers in large longitudinal cohorts].
We believe a global partnership between clinicians, researchers, and data scientists can meet these challenges, facilitating further identification, development and validation of speech-based biomarkers to enable researchers to apply artificial-intelligence algorithms for AD screening, detection, prediction, diagnosis, and monitoring. Existing consortia in related fields demonstrate that global collaboration and data sharing can indeed produce meaningful results (Table 1).
Selected examples of productive consortia efforts
| Consortium type | Weblink | Goals | Outcome |
|---|---|---|---|
| Enhancing Neuro Imaging Genetics through Meta Analysis (ENIGMA) Network | http://enigma.ini.usc.edu/ | Fifty active working groups dedicated to sharing ideas, algorithms, data, and information | Replicating promising findings among a network of researchers in the field of imaging genetics |
| Institutional Neuroimaging Data-Sharing Initiative | http://fcon_1000.projects.nitrc.org/ | Access to thousands of functional MRI datasets for their analysis | Standardized imaging data |
| Critical Path for Parkinson’s Consortium | https://c-path.org/programs/cpp/ | Links academic researchers with scientists from the pharmaceutical industry, government agencies, and patient-advocacy organizations | Facilitate the development of therapies with improved clinical endpoints |
| Linguistic Data Consortium | https://www.ldc.upenn.edu/ | Open network of universities, libraries, corporations, and government-research laboratories that supports language-related education, research and technology development | Creating and sharing linguistic resources, such as data, tools and standards |
| AphasiaBank | https://aphasia.talkbank.org/ | The development of standardized evaluation methods to guide the development and evaluation of effective methods for improving language usage in people with aphasia | Improvement of patient-oriented treatment of aphasia |
This manuscript summarizes interviews, surveys, and extensive correspondence with global leaders in the areas of dementia research, clinical trials, linguistics, and data analytics and outlines an ideal approach to generating a comprehensive, gold-standard set of speech- and language-based data. The end product of such an approach would be: 1) a rich, diverse, longitudinal, repeatedly measured, high-quality set of speech samples and 2) participant-characterization labels (such as imaging, blood-based biomarkers, or neuropsychological testing and clinical diagnosis) that researchers around the world can use to generate new diagnostic and prognostic algorithms. Here we focus on three broad areas: cohort selection, study design, and data collection and dissemination.
To obtain a set of speech samples that has the greatest utility for researchers, patients should range from healthy controls (HC) with no risk factors and HC with high risk factors [such as having the apolipoprotein E (APOE) 4 allele] to preclinical/suspected to prodromal/mild cognitive impairment (MCI) to mild AD and eventually to AD. Including disease controls, such as Parkinson’s or frontotemporal degeneration, is also important.
To use speech and language biomarkers as a measure of disease progression, the cohorts selected should allow for repeated, longitudinal, preferably high-frequency measurements. The cohorts should also include characterization using digital or traditional neuropsychological tests, genetic testing, MRI or PET imaging, and blood-based or cerebrospinal fluid (CSF) biomarkers. Finally, researchers should try to mitigate the burdens—of cost, time, and effort—on patients.
Given the diversity of potential approaches to collecting, processing, and analyzing speech- and language-based data, study design for a gold-standard dataset must carefully consider the attributes outlined in Table 2.
Key considerations for the collection and development of a harmonized speech and language dataset
| Cohort/patient selection | Study design | Data collection and dissemination |
|---|---|---|
|
|
|
| ||
SCD: subjective cognitive decline; PD: Parkinson’s disease; FTD: frontotemporal dementia
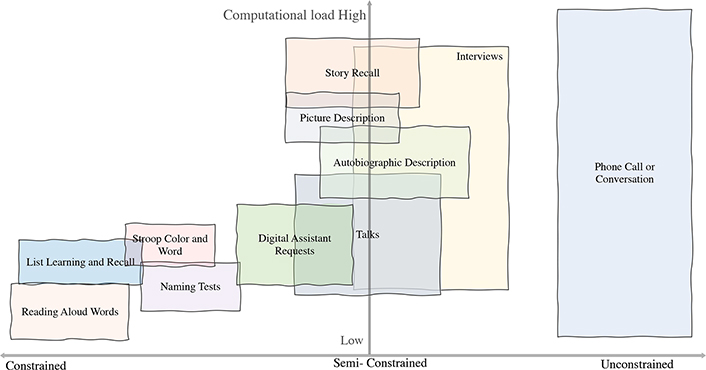
Voice recordings can be constrained, in which the subject is prompted to perform a clearly defined task such as recalling a list of words; unconstrained, in which speech samples are collected while the user is performing basic communication tasks such as talking with someone on the telephone; or somewhere in between (Figure 1).
Each of these approaches carries a different cognitive load and highlights different aspects of speech or language, and likewise provides the ability to reveal changes in speech, language and interaction patterns in addition to changes across multiple cognitive domains. A dataset that combines the raw data from these assessments will provide the largest variety of speech and language features for analysis.
Researchers must consider which aspects of speech and communication they can reliably and consistently collect across different cohorts using different technology platforms. They should also develop standardized protocols for administering, recording, labeling, and annotating (where applicable) the voice samples. These standardized protocols will truly permit meaningful comparisons.
The utility of the speech and language dataset depends on researchers’ ability to access and analyze it while still maintaining patient privacy and data security. An ideal data sharing platform should address aspects of access (open, limited, nested) and enable virtual processing of datasets within the repository to maintain patient privacy. Possible approaches include allowing researchers to process raw data, run their algorithms, and extract features on a remote privacy-maintaining server versus downloading onto individual computers. Moreover, different levels of processing could be allowed for each interested party, such as limiting access to phonetic and acoustic features, thereby preserving subjects’ privacy as much as possible. Approaches to maintaining privacy are evolving and best practices should be implemented and updated when appropriate. Existing voice repositories, such as the Linguistic Data Consortium and DementiaBank, can serve as an example [4, 5].
A comprehensive, harmonized, open-access speech-sample repository covering well characterized, large, diverse cohort(s) of subjects can enable the development of better biomarkers that characterize the onset and progression of AD (and other neurodegenerative diseases) in a minimally invasive, low-cost way. At the same time, democratizing speech and language analytics must be a joint effort: at every step along the way, collaboration and cooperation are key. Together, these can facilitate truly seismic shifts in neurodegeneration research.
AD: Alzheimer’s disease
MRI: magnetic resonance imaging
PET: positron emission tomography
The authors would like to thank the companies and investigators who provided their insightful expertise for the development of this commentary. The authors would also like to thank Dr. Niranjan Bose, Health and Life Sciences, Gates Ventures for thoughtful discussions and critical review of the manuscript. Also, the authors would like to thank Visar Berisha, Julie Liss, Shira Hahn, and Jessica Robin for their help in creating Figure 1. Writing assistance was provided by Emily Lieb.
NLB, LK, KM, SP and HF contributed to the conception and design of the commentary. NLB, LK and SP wrote the first draft of the manuscript. SP created the tables. All authors contributed to manuscript revision, read and approved the submitted version.
The authors declare that they have no conflicts of interest.
Not applicable.
Not applicable.
Not applicable.
Not applicable.
Funding was provided through the Diagnostics Accelerator, an initiative funded by a coalition of funders including the Alzheimer’s Drug Discovery Foundation and Gates Ventures. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
© The Author(s) 2020.
Copyright: © The Author(s) 2020. This is an Open Access article licensed under a Creative Commons Attribution 4.0 International License (https://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, sharing, adaptation, distribution and reproduction in any medium or format, for any purpose, even commercially, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.

Lindsay M. Quandt, Cyrus A. Raji
Bessi Qorri ... Joseph Geraci
Siao Ye ... Reza Hosseini Ghomi
Honghuang Lin ... Rhoda Au
Sheina Emrani ... David J. Libon
Margaret Ellenora Wiggins ... Catherine C. Price
Larry Zhang ... Reza Hosseini Ghomi
Robert Joseph Thomas ... Rhoda Au
Taylor Maynard ... Sandy Neargarder